オブジェクト指向とは
この記事では、初学者がオブジェクト指向について学んだことをまとめたものです、ご了承ください。
目次
オブジェクト指向誕生の背景
技術が進歩していくことでプログラムが複雑化していく一方で、それに伴ってバグの発生頻度も増えていくことになる。 プログラムの一箇所だけを修正したいだけなのに、他のコードも合わせて修正する必要があった。 プログラムを追加したら、他のプログラムにも影響してバグが発生した。 などの様々な要因を解消できないかと開発されたのがオブジェクト指向プログラミング
オブジェクト指向とは
オブジェクト指向とは、定められたルールではなく概念といった考え方のこと。 オブジェクト指向でコードを書く理由は、変更に柔軟に対応できるようにするためです。 誕生の背景にある問題を解消すべく、独立性・再利用性・拡張性を兼ね備えた「いかに効率よく、分かりやすく開発ができるか」を突き詰めた考え方。
オブジェクト指向の考え方
そもそもオブジェクトとは、関連する変数(値)とメソッド(動作)をまとめて、そのまとまりに名前をつけたものです。 オブジェクト指向では、そのモノを定義して、それらがどのように動作するのかを設計していくことからプログラミングが始まる。 設計とは、 モノの振る舞いや定義が明確になっているか 利用する人が分かりやすいような形になっているか 利用者が増えても拡張性の高いものになっているか 違うモノとの関連性でバランスが崩れないか
オブジェクト指向では3つの重要な要素がある。 1,独立性(カプセル化) 他のプログラムから干渉されないように作る考え方 2,再利用性(継承) 同じようなプログラムは共通化して使う考え方 3,拡張性(ポリモーフィズム) 凡庸的な形にできるようにしようという考え方
オブジェクト指向の具体例
5種類のキャラを作る
例えば、固有の職業を持った複数の主人公たちから一人を選んでストーリーを始めるRPGゲームを作るとする。 職業の種類は、剣士・魔法使い・格闘家・弓使い・槍使いの5つ。




これらの職業は戦い方が異なるため、それぞれに定義が必要になってくる。しかし、いきなり5種類のキャラを作成するのではなく、キャラごとの特徴を精査して設計図をプログラミングしていく。 このときの設計図をクラスという。 クラスとは、モノの構成要素と振る舞いが定義されている、複数のデータの集合体からなるデータ構造体のことをいう。 構成要素(データ) = プロパティ(属性) 振る舞い = メソッド(処理)
プロパティには、名前・年齢・出身国・HP・声 メソッドには、攻撃する・ジャンプする・声を発する
というような設計をする。これらは全てのキャラの骨組み(初期キャラクター)となる。
5種類のキャラを設計する。
骨組みの初期キャラクタークラスから新たなクラスを作る場合、継承を使う。 継承というのは、初期クラスの機能つまりプロパティ、メソッドを引き継いだ新たなクラスを作ること。 親クラス(スーパークラス) ↓ 子クラス(サブクラス) ※この時点ではまだ同じ機能
Aの子クラスに特有のプロパティを追加
剣士 名前:剣太郎、年齢:18歳、出身:日本、HP:100、声:男性
メソッドを追加
攻撃する→剣を振る、声を発する→「セイヤーッ!(松岡●丞風)」
Bの子クラスに特有のプロパティを追加
弓使い 名前:弓子、年齢:17歳、出身:日本、HP:100、声:女性
メソッド追加
攻撃する→弓を射る、声を発する→「ハッ!(沢城●●き風)」

剣士キャラであれば、攻撃は「剣を振る」になり、声を発するは「男性」キャラなので、男性の声に設定する。 クラスのメソッドを子クラスで上書きすることをオーバーライドという。 このようにオーバーライドによる継承したキャラが違う動きをする特性のことを拡張性(ポリモーフィズム)という。
また、プロパティのHPは攻撃を受けたときのみ通るメソッドからでしかいじれなくする。これは、何らかの形で外部から値をいじれてしまったら最大HPを超える値を入れることができてしまい、バグ発生につながるからです。 このようにプロパティのデータに正しい値が入ってるかをメソッドで判断して保護することで、他のプロプログラムから干渉されないように作ることができます。 このような独立性を持たせることを独立性(カプセル化)という。
キャラ以外でも、、、
キャラ以外でもステージもモノとして捉えることができる。 ステージの場合だと、プロパティには、気候、モンスターエンカウント、土地の広さなど。メソッドには、気候によるキャラへの状態異常、エンカウントするモンスターの種類など。多くの多種多様なステージが作れる。 上記の例はとても簡素なため、もはや個別に設定すればいい話になるが、実際の開発現場では、キャラクターやステージの共通部分が膨大になるため、こういった継承を使うことで手間を省くことができる。 もし、キャラやステージの仕様が変更する場合、継承していなければ、すべてのキャラのプロパティを手直ししなければならない。それが継承していれば、初期キャラクターのクラスの1ヶ所だけ直せばよくなる。
まとめ
このように継承をすることによって、共通のプロパティ、メソッドをまた書かなくてよくなるのでコードの重複を減らしてコードの再利用性を高めることができる。モノとして考える理由は、共通する特徴ある者同士をまとめて、プログラムを共通化するため。
共通化つまりクラスでまとめることにより、独立性、再利用性、拡張性がそれぞれ高まることになる。 つまり継承によって機能を共通化して再利用しやすくして、カプセル化によってプログラムが独立でき、ポリモーフィズムによって機能を拡張しやすくなり、よって『効率よくわかりやすく開発』することができるようになる。
オブジェクト指向のメリット
- 同じようなモノを複製しやすい
- 機能の変更・追加がしやすい
- 大人数で開発するときに便利
- 大変な作業を無くす
オブジェクト指向のデメリット
- 理解するのが難しい
- クラス別に処理する必要があり、詳細なクラス分けは返ってコードの複雑化に繋がってしまう
- 継承という仕組みによって、どこのコードが実行されているのかが分かりにくい(特に読み手)
- オブジェクトコードの肥大化
- オブジェクト指向のメリットを活かした設計能力が必要になる
感想
オブジェクト指向の書籍を読まずにwebの情報だけで学んだため、改めて書籍でも勉強していきたい。 現時点では、実務においてのオブジェクト指向によるプログラミングがどれほど有用なものなのかは分からず、理論とともに実戦経験がなければ、それは測れないと思いました。 ただ、オブジェクト指向を用いられる言語を学ぶ上では、とても大切な考え方なので今後とも勉強していきたい。
オブジェクト指向を用いられる言語の一例
Java、Ruby、Python、PHP、C++、JavaScript、Swift、Eiffel
また、オブジェクト指向以外の概念には、手続き型プログラミング、関数型プログラミングというものもある。
参考
プログラミング初学者がデバッグを知る
※この記事はデバッグについての忘却録です。
※この記事の内容は初学者による筆者個人の見解です。ご了承ください。
初学者における「ロジックを理解する」について
制作物を見てもらう前提の話ですが、初学者におけるプログラミングの学習練度を実際の現場で働かれている方が測る一つの手法として、自分で記述したコードの「ロジックを理解している」かどうか、で判断するという意見をお聞きします。
しかし、実際は初学者が一からロジックを組み立ててコーディングするのは難しく、どうしても実装したい機能をブラウザで検索し、参考元からの一部抜粋(コピぺ)の塊になりがちです。自分の書いたコードのレビューなんかも怪しいところです。(自分はそうだった。) とりあえずコーディングしていき、エラー解消等をしていって動いたからオッケーが往々にしてあると思います。 それ自体に否定的になるわけではなく、自分で書いたコードの「ロジックを理解している」という観点とはまた別の話になるのかなと思います。
自分の培ってきたものを見て貰いたいのに、そんな曖昧な状態で判断して頂くのは、相手にとっても自分にとっても良いものではありません。 それ以上に、一緒に働かせてもらえるようになってからが大変になってしまいます。
そんな状況を改善するために実施していきたい2つの方法があります。それが、
デバッグ と 自分の記述したコードにコメントアウトを残す ことです。
デバッグとは
デバッグは、システムやプログラムのバグを取り除くことを指す。 バグを発見するための専用ソフトウェアをデバッガという。
テストとデバッグ
テストとデバッグは、意味合いが似ているので混同しがち。しかし、両者には違いがあります。
その違いとは、テストはバグを発見することだけではなく性能や機能を評価するためにも行われることです。デバッグはパフォーマンスの評価はしない。(テストの手法自体は多岐にわたる)
コメントアウトを残す
ここで行うことはコードレビューではありません。 記述したコードがどんな動作をするのかをコメントアウトで残すことで、理解を深めることです。
まとめ
「ロジックを理解する」ことにおいて、大切なのは自分の記述したコードのデバッグができるようになること。(デバッグのやり方を覚える事) そして、学習中のコーディングでは理解の曖昧な関数や機能には積極的に(どういった動作をするのかを)コメントアウトを残す。
git-flowとGitHub Flowの違い
git-flow,GitHub Flowは「Git/GitHubのワークフロー」であり、厳密な規則ではない。
開発規模や人数によって適切なワークフローを用いることで、複数人でのバージョン管理システムの運用を円滑にすることができる。
git-flow
「git-flow」はVincent Driessen氏の「A successful Git branching model」を基にしたワークフロー。 他のワークフローと比べると大規模で複雑な構成になっている。 開発者が4人以上の場合に適している。
ブランチの種類と用途
メインブランチ
メインブランチには「master」と「develop」の2つのブランチがある。 これらのブランチは常に存在する。
- master(main)
リリース済みのソースコードを管理する
- develop
開発中のソースコードを管理する
サポートブランチ
タスクごとに「feature」「release」「hotfix」のいずれかのブランチを作成し、作業を行う。
feature 機能実装や開発作業を行う
release リリース準備作業を行う
hotfix 緊急の修正やバグ修正を行う
開発フローの例
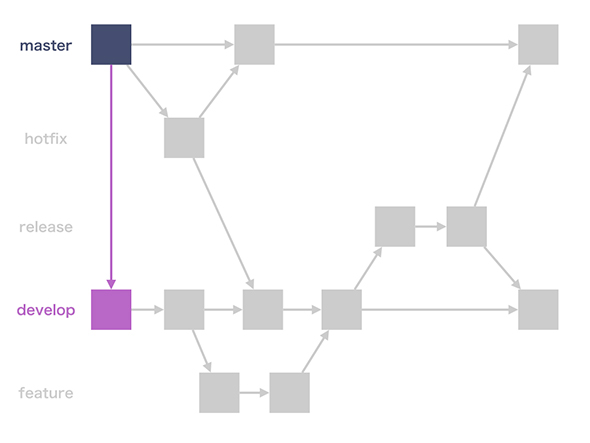 1,developブランチを作成
master(main)ブランチからdevelopブランチを作成
1,developブランチを作成
master(main)ブランチからdevelopブランチを作成
2,機能を実装する developブランチから、featureブランチを作成 機能実装後、コミットはfeatureブランチに対して行う
3,機能実装を完了する featureブランチでの作業が完了したら、featureブランチをdevelopブランチにマージする マージ完了後にfeatureブランチを削除する
4,リリース準備を始める 機能実装が終わりリリースできる状態になったら、developブランチからreleaseブランチを作成する
5,リリース準備を完了する リリースブランチでの作業が完了したら、releaseブランチをmasterとdevelopブランチにマージする マージ完了後にreleaseブランチを削除
6,緊急の修正作業を開始する リリース後に緊急の修正作業が発生した場合は、masterブランチからhotfixブランチを作成し、修正作業を行う マージ完了後にhotfixブランチを削除する
GitHub Flow
「GitHub Flow」は「GitHub」の開発で使用されているワークフローであり、「git-flow」に比べてシンプルな構成になっている。
開発人数が1~3人で1日に複数回デプロイを行うようなWebアプリケーションの開発に適している。
6つのルール
- masterブランチは常にデプロイ可能である
- 作業用ブランチをmasterから作成する
- 作業用ブランチを定期的にプッシュする
- プルリクエストを活用する
- プルリクエストが承認されたらmasterへマージする
- masterへのマージが完了したら直ちにデプロイを行う
開発フローの例
 1,開発作業を行う
GitHub Flowでは、全てのブランチをmasterブランチから作成する
ブランチ名は、何の作業を行っているかが分かる名前にする。また、作業用ブランチは定期的にリモートリポジトリにプッシュするようにする。これによって、他の開発者の作業状況を把握できるようになる
1,開発作業を行う
GitHub Flowでは、全てのブランチをmasterブランチから作成する
ブランチ名は、何の作業を行っているかが分かる名前にする。また、作業用ブランチは定期的にリモートリポジトリにプッシュするようにする。これによって、他の開発者の作業状況を把握できるようになる
2,Pull Requestを行う 作業用ブランチをmasterブランチへマージできる状態になったら、プルリクエストを作成して他の開発者にコードレビューを依頼する。そして、プルリクエストが承認されたらmasterへマージする
GitHub Flowを使用した開発では、プルリクエストを積極的に活用する。作業完了後のコードレビューだけではなく、作業途中の実装への助言を求める場合などにも使える
3,デプロイする masterへのマージが完了したら直ちにデプロイを行う
まとめ
git-flowは4人以上での開発の際に用いる GitHub Flowは1~3人での開発に用いる マージの際はPull Requestをする(GitHub Flowの場合は作業途中でも有用なため積極的にする)
- master(main)・・・ユーザーが使う製品
- hotfix・・・バグ修正用ブランチ、masterからクローンしてくる
- release・・・リリース用
- develop・・・featureブランチの集まり
- feature・・・作業ブランチ
参考
https://www.atmarkit.co.jp/ait/articles/1708/01/news015.html#02
gitコマンドとか
※常時編集
新規リポジトリ作成からGithubへのpushまで
$ git init #リポジトリを新規に作成(既に存在するリポジトリをサイド初期化) $ git add -A #オプションをつけることでまとめて登録できる $ git commit -m "Initial commit" #最低一回はコッミトしないとpushできない $ git remote add origin <github.url> #リポジトリの紐付け $ git push -u origin master #リモートリポジトリにpush
補足
$ git add
$ git addは、指定したファイルをインデックスに登録してコミット対象にするコマンド。
$ git add <file> $ git add text.txt
$ git add -u と $ git add -A と $ git add .
オプションを付けることで、まとめて登録することができる。
git add -u (git add --update) バージョン管理されていて、変更があったすべてのファイルがaddされる 変更されたファイル、削除されたファイルがaddされる バージョン管理されていないファイルはaddされない 新しく作られたファイルはaddされない
git add -A (git add --all) 変更があったすべてのファイルがaddされる 変更されたファイル、削除されたファイル、新しく作られたファイル、すべてがaddされる
git add . カレントディレクトリ以下の、変更があったすべてのファイルがaddされる カレントディレクトリ以下の、変更されたファイル、削除されたファイル、新しく作られたファイル、すべてがaddされる
-u は --set-upstreamの省略 このオプションをつけるとローカルリポジトリの現在のブランチの上流をorigin master に規定したことにる。 このオプションをつけると、次からは git push だけで上記のコマンドと同じことを実施できる。さらに、git pull だけでも git pull origin master と同じ意味になる。
originとは リモートリポジトリのアクセス先に対してGitがデフォルトでつける名前のこと。
ざっくりコマンド一覧
ローカルのリポジトリの内容をリモートのリポジトリに送り込む $ git push リモートのリポジトリの内容をローカルのリポジトリに取り込む チーム開発などをしていて他人のbranchを確認するときなどに使う $ git fetch リモートのリポジトリの内容をローカルのリポジトリに取り込み、 次に、現在のローカルのブランチに対して、それに対応するリモートのブランチをマージする $ git pull ローカルの変更を確認する $ git status リモートとローカルのファイルの差分を抽出する $ git diff <ファイル名> commitの変更履歴をみる $ git log リモートにプッシュ $ git push origin <ブランチ名> addの取り消し $ git reset HEAD <ファイル名> commitの取り消し $ git reset --hard HEAD^ commitの打ち消し $ git revert <コミットのハッシュ値> ローカルでブランチを作成 $ git branch <ブランチ名> ローカルでブランチを切り替え $ git checkout <ブランチ名> ローカルのブランチをリモートに反映 $ git push -u origin <ローカルのブランチ名> ブランチをマージする $ git merge <ブランチ名>
管理しないファイルをGitの管理から外す
.gitgnoreファイルに指定することで、ファイルをGitの管理から外すことができる。 どういったファイルを管理するのか?
- 自動生成されるファイル
- パスワードが記載されているファイル
Gitのリモートリポジトリに間違えてpushしてしまった時の解消法(正しい方法なのかはわからない)
コミットログの確認
$ git log --oneline a6ba0a0 間違えてpushしたコミット e04f025 commitB 11b03cd commitA
本来作業するはずだったブランチを作成、または、移動しそこでpushする
$ git checkout -b feature/branch # branchの作成&切り替え $ git push origin feature/branch # リモートへpush
間違えてpushしてしまったcommitをresetして強制pushする
$ git reset --hard e04f025 $ git push -f origin develop
ブランチとリポジトリの相関図
 リモート追跡ブランチ (remote-tracking branch)」と「上流ブランチ (upstream branch)」
リモート追跡ブランチは「ローカルリポジトリにあって、他のリポジトリの状態を追跡するブランチ」のこと
上流ブランチは「引数なしで git pull したとき対象になるブランチ」のこと
リモート追跡ブランチ (remote-tracking branch)」と「上流ブランチ (upstream branch)」
リモート追跡ブランチは「ローカルリポジトリにあって、他のリポジトリの状態を追跡するブランチ」のこと
上流ブランチは「引数なしで git pull したとき対象になるブランチ」のこと
上の図でいうと、origin/masterはローカルブランチmasterの上流ブランチ
Git GraphというVScodeの拡張機能
Gitのコミットグラフをみれる拡張機能。慣れないうちはコミットグラフが常に可視化されているのは心強い。(はちゃめちゃなコッミトの仕方の防止に繋がる)

マージコンクリフトの解決方法
マージコンクリフト( Merge Conflict )には2種類の場合がある。 1、同じファイルの同じ行の競合 2、削除したファイルと編集されたファイルの競合
※「競合」( Conflict )とは、言葉の通り互いに競り合うことを意味する。
同じファイルの同じ行の競合
developブランチとfeatureブランチが存在していて、それぞれのブランチの同じ名前のファイルの記載内容が異なっている場合。 例えば、作業ブランチで編集したconfig/routes.rbを編集してマージした際、
$ git merge <ブランチ名> Auto-merging config/routes.rb CONFLICT (content): Merge conflict in config/routes.rb Automatic merge failed; fix conflicts and then commit the result.
表示されている通り、自動マージが失敗したので、競合を修正してから手動でコミットしてください。と言われる。 以下のコマンドでどのファイルを編集すればいいか確認。
$ git stutas
On branch develop
Your branch is up to date with 'origin/develop'.
You have unmerged paths.
(fix conflicts and run "git commit")
(use "git merge --abort" to abort the merge)
Changes to be committed:
new file: app/assets/javascripts/reviews.coffee
~ 省略 ~ #これらのファイルはコンフリクト起こさずに自動マージできたファイル
new file: spec/views/reviews/show.html.slim_spec.rb
Unmerged paths:
(use "git add <file>..." to mark resolution)
both modified: config/routes.rb #このファイルを修正する
マージを中止する場合 → $git merge --abort
コンフリクトを解消したら → $git add <file>
対象ファイルを開くと、コンクリフトを起こしている部分は以下のように表示される
<<<<<<< HEAD
root to: 'static_pages#top' |
root to: 'static_pages#home' | #作業ブランチでの変更内容
resources :static_pages |
|
# get 'static_pages/top' |
# get 'static_pages/home' |
=======
root to: 'reviews#index' | #マージ先のブランチでの変更内容
resources :reviews |
>>>>>>> feature/branch
end
今回は作業ブランチでの変更内容は全部消して問題なかったので削除 編集したファイルをステージングする(これをしないとGitがコンクリフトを解消したことに気づけない)
$ git add config/routes.rb
$git statusでUnmerged paths:の警告が消えているのを確認
ファイルはChanges to be committed:の一覧に追加されている
そして、コッミトしてプッシュすれば完了!
$ git commit -m "コンフリクト解消" $ git push origin develop
削除されたファイルと編集されたファイルの競合
developブランチのXXXファイルは削除したけど、featureブランチのXXXファイルは削除することなく編集した場合。
$ git merge feature CONFLICT (modify/delete): XXXファイル deleted in HEAD and modified in feature. Version feature of XXXファイル left in tree. Automatic merge failed; fix conflicts and then commit the result.
メッセージ内容は(同じファイルの同じ行の競合と)少し異なりますが、言いたいことは同じで自動的なマージは失敗したので、適性に競合してからコミットしてくださいということ。
$ git status
You have unmerged paths.
(fix conflicts and run "git commit")
(use "git merge --abort" to abort the merge)
Unmerged paths:
(use "git add/rm <file>..." as appropriate to mark resolution)
deleted by us: XXXファイル
no changes added to commit (use "git add" and/or "git commit -a")
こちらのコンフリクトも$git merge --abortでマージを取り消すことができる
今回はファイルを削除したままにしたいので、以下のコマンドを入力する。
$ git rm XXXファイル XXXファイル: needs merge rm 'XXXファイル'
$ git rmはgitの管理下にあるファイルを削除するコマンド。標準のUNIXコマンドにあるrmのgit版にあたるもの。
On branch master All conflicts fixed but you are still merging. (use "git commit" to conclude merge)
あとは同じようにコミットするだけ
片方のブランチの変更内容を採用する
チェックアウトしている側のブランチの変更を採用したい場合 $ git checkout --ours {ファイル名} 相手側のブランチの変更を採用したい場合
$ git checkout --theirs {ファイル名}
mergeとrebase
どちらもブランチ元に統合する機能。
- merge
- 非破壊的操作(情報が消えることはない)
- 既存のブランチは変更されない
頻繁にブランチしたりmasterが動いたりする場合だと、コミットグラフが乱雑する
rebase
- コミットグラフはきれいになるが、消える情報がある
- pushされたブランチをrebaseすとるpushできなくなる
コミットログが綺麗になるのは一見するといいことのように思えるが、そもそも Git はブランチが分岐するような非直線的な履歴のために作られ、またそれを推奨している。リポジトリにおいて大切なのは履歴の正確性。不具合が起きた時に不必要な履歴は存在しない。 ただどちらのコマンドが有用的になるのかは、開発環境・状況によって異なるだろうし、そこの判断は追々学んでいきたい。
補足
同じファイルの同じ行の競合については、Ruby on Railsでの開発の時、実際に起こった状況をもとに解決したものです。 削除されたファイルと編集されたファイルの競合に関しては、情報をまとめただけです。
参考 Git のマージコンフリクトを解決する方法 mergeとrebaseの違い なぜ git rebase をやめるべきか - Frasco [Git]コンフリクトをよりスマートに解消したい!